Time Complexity (+ what does O(log n) mean?!)
02 Feb 2022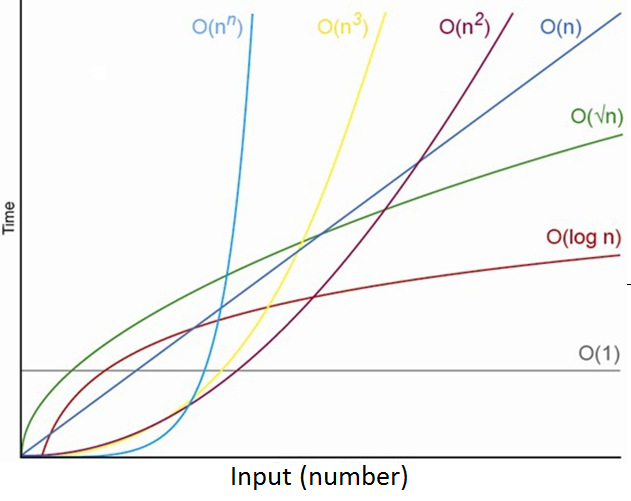 Source: Big ‘O’ & Time Complexity
Source: Big ‘O’ & Time Complexity
Time Complexity & Big O
Time complexity refers to how long an algorithm takes to run. The important thing here is it measures the run time of an algorithm respective to the input size.
Big O is a way to describe the speed of an algorithm as input size nears infinity (asymptotic analysis). The unit of measurement is the number of operations performed by the CPU, rather than the absolute time in seconds or minutes. One CPU operation refers to one read/write operation on a memory address, which is done in O(1) time.
In other words, Big O is a measure of scalability, i.e. how effective the algorithm is as input size increases massively.
The ‘O’ comes from ‘Order of the function’.
It’s important to note the importance of not only Time Complexity but also Space Complexity which is how much memory an algorithm consumes. This is also denoted by Big O.
Common Complexities
Common complexities in order from fast to slow are:
- Constant: O(1)
- Logarithmic: O(log n)
- Linear: O(n)
- Log-Linear: O(n log n)
- Quadratic: O(n2)
- Cubic: O(n3)
- Exponential: O(2n)
- Factorial: O(n!)
O(1) complexity means that an algorithm will always execute in the same amount of time regardless of input size. If it had 3 operations when n size was 1, it will still have 3 operations to complete when n size is 1,000,000.
Meanwhile, O(n) complexity denotes an algorithm whose number of operations grows linearly in direct proportion to the input data. For example, printing the elements of an array: If the array has 1 item print 1 item. If there are 1,000,000 items, need to print 1,000,000 times.
O(n2) complexity describes an algorithm whose performance is directly proportional to the square of the input size n. An example is nested for loops: if array size is 10, number of operations becomes 100. If n is 1,000, there will be 1,000,000 operations.
It is important to note that the complexity of an algorithm usually denotes the worst-case complexity, instead of the average case.
For example, some sorting algorithms have varying time complexities depending on how they are initially sorted. In such cases, they may have O(n log n) average run-time, and O(n2) worst case run-time, in which case the latter becomes the algorithm’s complexity.
O(log n)
Here, I want to talk about O(log n) just because I have found logarithms to be scary as someone who is not that fond of anything mathematics 😅.
O(log n) basically means that the time complexity of an algorithm is the Logarithm of input size n.
Logarithm is a mathematical concept widely used in CS, and is defined by the following equation.
logb(x) = y if and only if by = x
In CS, the base is always 2 which represents a binary logarithm, so the equation becomes:
log(n) = y if and only if 2y = n
Here, y is represents the time taken to run the algorithm while n represents input size.
The pattern goes as follows:
20 = 1 ——> log(1) = 0
21 = 2 ——> log(2) = 1
22 = 4 ——> log(4) = 2
23 = 8 ——> log(8) = 3
24 = 16 ——> log(16) = 4
Here, the numbers 1, 2, 4, 8, 16... represents input size n while 0, 1, 2, 3, 4..., the log of these values, represents the complexity of the algorithm. We can see that as the size of n doubles, the log value (exponent of 2) increases by 1.
2x = N ——> 2x+1 = N * 2
This means that as N increases (doubles), the log value of N (log n) only increases by a small amount (1). 220 == 1M, while 230 == 1B, which is a huge difference but the log(n) difference is only 10.
This is why O(log n) algorithms are very efficient, only coming after O(1) but way more so than O(n). This is because when input size doubles, the number of CPU operations only increases by 1.
O(log n) algorithms
Logarithmic time complexity is typically seen in algorithms that repeatedly cut the input size in half until it reaches an answer. Examples are array binary search, or the binary search tree.
e.g. If the array size was 8 and a binary search was performed, it would be cut in half 3 times until the size was 1. (23 = 8)